Boyuan Sun (孙博远) is currently a 3rd year Ph.D. candidate at Nankai University, supervised by Prof. Qibin Hou and Prof. Ming-Ming Cheng. He received his bachelor's degree from the School of Computer Science and Technology at Xidian University in 2021. And now he is taking the Master-Ph.D. combined program in Nankai University. His research interests include Computer Vision and Multimodal Large Language Model, particularly focusing on multi-modal visual perception, vison-language model, semi-supervised learning, etc.
Internship Experience
 ByteDance
ByteDance
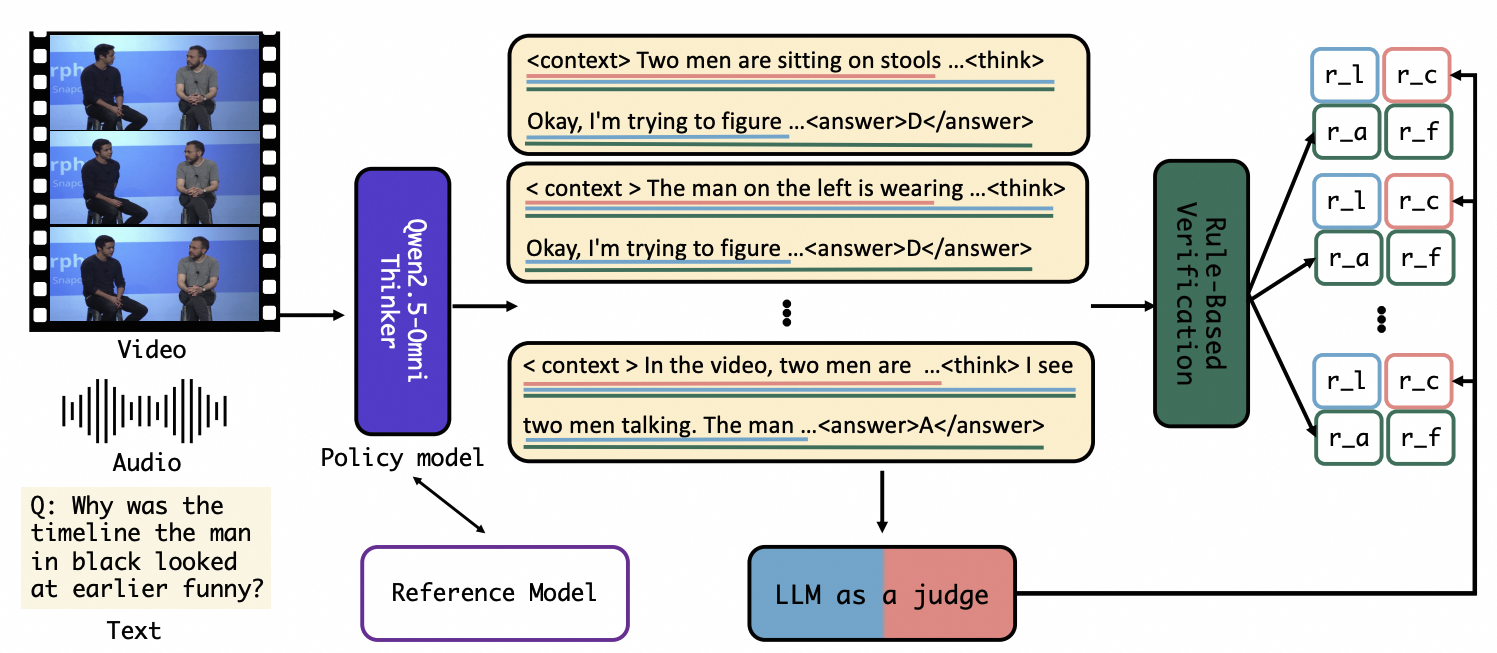
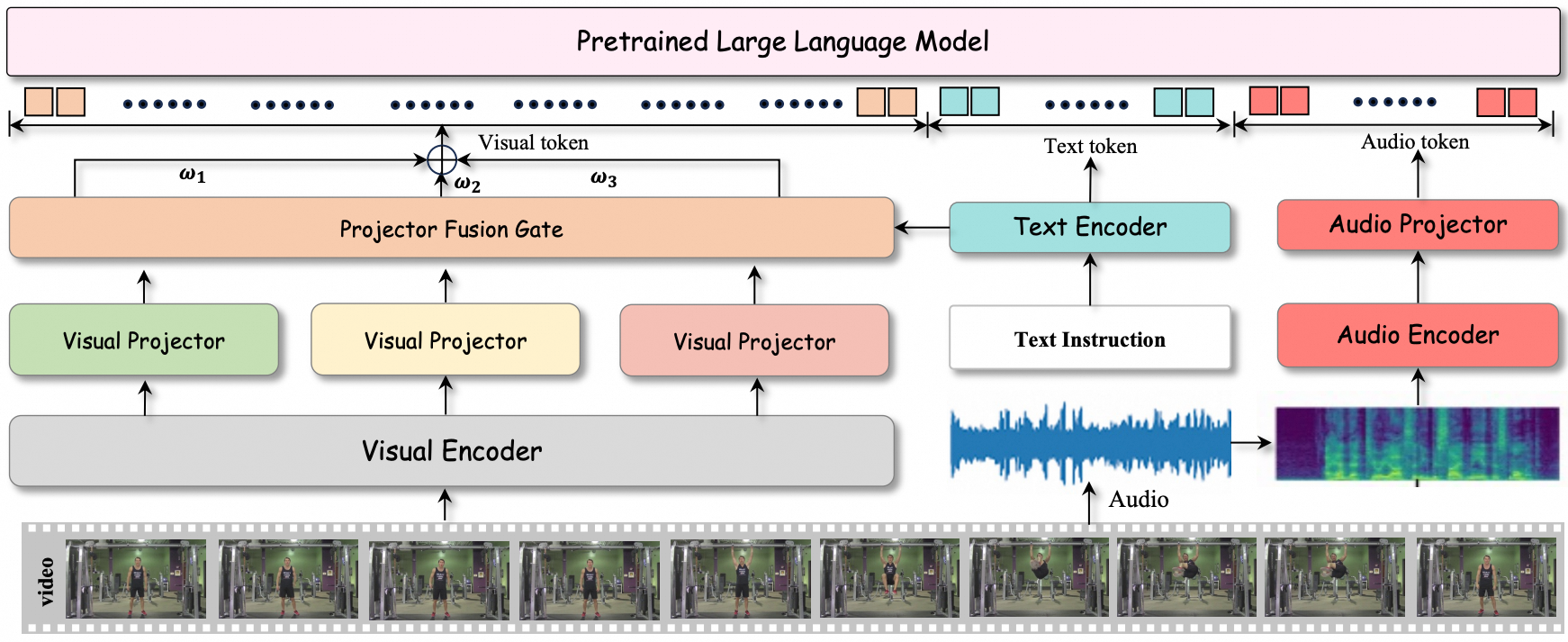
Working on streaming video understanding and omni models. Focusing on agentic RL and on-policy training for streaming video.
 Shanghai AI Laboratory
Shanghai AI Laboratory
Working on Science Discovery Agent System, focusing on MLE agentic model design, Data analyze agent, and agentic model training.
 Tongyi Lab, Alibaba
Tongyi Lab, Alibaba
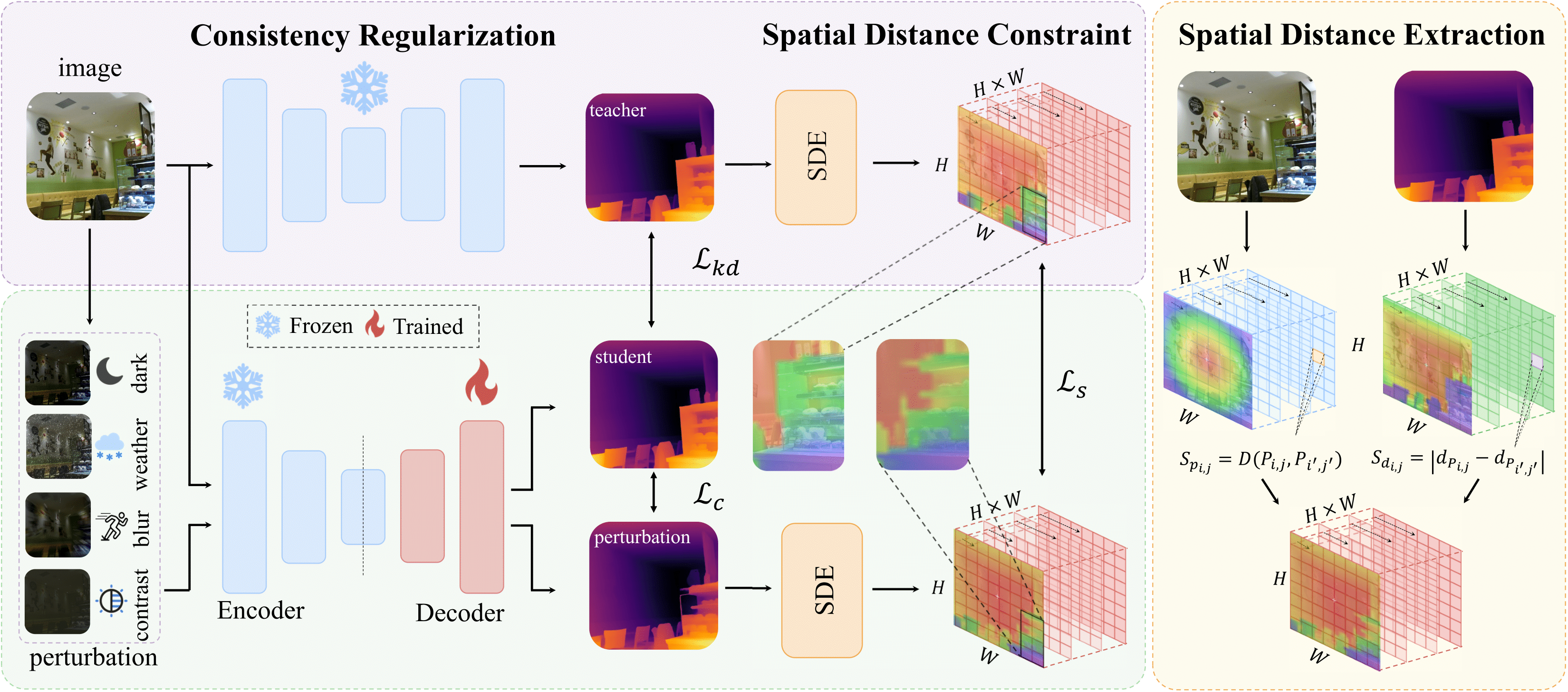
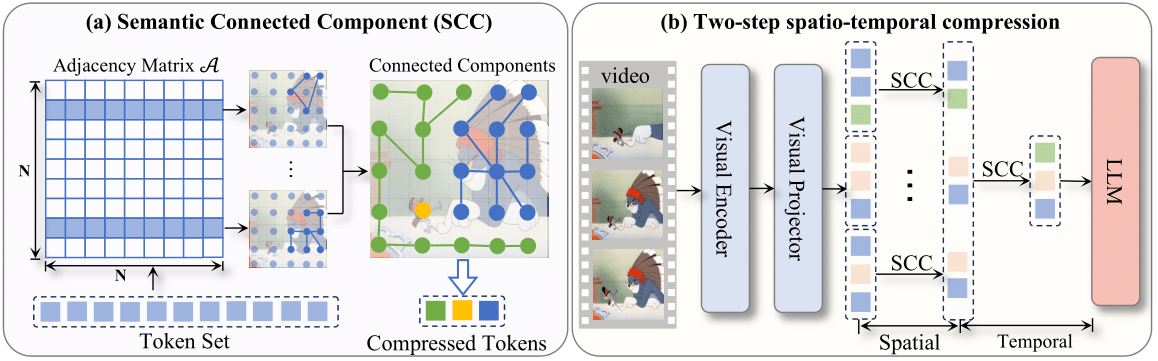
Focused on video understanding techniques, especially on training-free token compression, omni model architecture, and fine-grained object understanding for large multimodal models.
Selected Publications
* Equal contribution. # Corresponding author.

Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
Technical Report

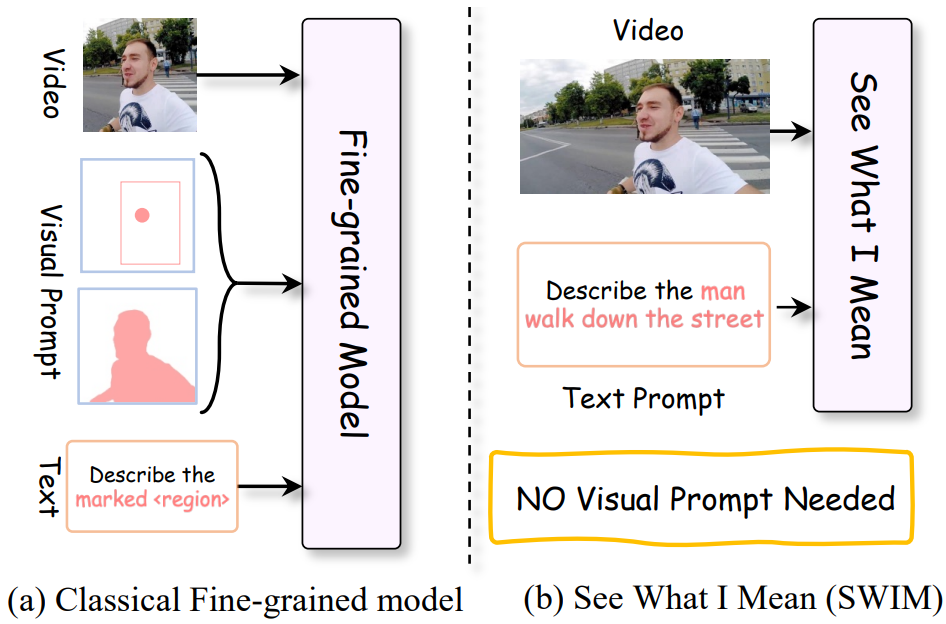
See What I Mean: Aligning Vision and Language Representations for Video Fine-grained Object Understanding
IEEE Computer Vision and Pattern Recognition 2026 (CVPR 2026)